개발 etc
분산환경에서 DB 기본키(PK)는 어떤 ID 생성 전략으로 만들어야할까? (UUID,ULID,TSID...)
묠니르묘묘
2023. 9. 3. 19:08
보통 개발 편의성을 위해 Oracle의 Sequence, MySQL의 auto_increment 로 숫자를 1씩 증가시키는 것으로 만든다.
이것은 어떤 문제점이 있을까?
- 외부에서 해당 시스템 PK를 예측하기 쉬워져서 SQL Injection 문제
- Sequence, auto_increment는 중앙 집중식으로 값을 생성하는 방식이므로 DB에 의존적이게 되어 확장성이 제한되는 문제
- 서비스 폭풍성장 시, ID 고갈되는 문제 (BIGINT 최댓값은 4,294,967,295 이고, unsigned BIGINT라면 18,446,744,073,709,551,615)
- 데이터베이스 변경의 어려움
- DB가 2대 이상일 때 중복 문제
💡 MySQL 5.7 이하 버전에서는 AUTO_INCREMENT counter 값을 메모리에 저장하였기에 재기동한다면 이 값이 소멸된다. 따라서 0부터 시작하게되는 문제가 발생한다.
💡 MySQL 8.0 이후부터는 AUTO_INCREMENT counter 값을 디스크에 저장하는 방식으로 변경되었다.(redo log에 저장) 따라서 재기동되더라도 counter값이 남아있기에 중복문제가 발생하지 않는다.
분산환경에서 유일성이 보장되는 ID를 만드는 방법은 어떠한 것이 있을까?
🚀 다중 마스터 복제(multi-master replication)

- DB의 auto_increment 기능을 활용하고, 1씩 증가하는 것이 아닌 서버의 수 k만큼 증가시키는 방법
- 각 DB서버가 다음에 만들 ID값은 자신이 생성한 이전 ID값에 전체 서버의 수 k를 더한 값
- 위 그림에서는 DB서버가 2개이므로 k = 2 가 됨
- 규모 확장성을 어느정도 해결
😈 단점
- 여러 데이터 센터에 걸쳐 확장 어려움
- 시간 흐름에 맞춰 ID값을 커지도록 보장할 수 없음
- 서버 추가 및 삭제 할 때도 잘 동작하도록 만들기 어려움
🚀 UUID
UUID값 예시 : bb6266a8-09aa-4c90-b597-05f1cc958acd
- 컴퓨터 시스템에 저장되는 정보를 유일하게 식별하기 위한 128비트짜리 수
- UUID 값은 충돌 가능성이 매우 낮음 (중복 확률 0.00000000006% 인데 운석 맞을 확률임)
- 서버 간 조율 없이 독립적으로 생성 가능
- 알파벳은 소문자로 표현되며, 입력시 대소문자를 구분하지 않음
👍 장점
- UUID 생성은 간단
- 동기화 이슈 X
- 규모 확장 쉬움
😈 단점
- ID값이 128비트로 길며, 용량도 큼
- 대규모 테이블에서 저장공간 많이 차지
- 시간순 정렬 X
- 숫자가 아닌 값 포함
- UUID 값은 문자 단위로 비교되기 때문에, 정수와 비교하면 성능이 느림 (2.5배 ~ 28배 성능 저하)
- MySQL(innoDB) 인덱스는 B+Tree 구조로써 순차성에 강한데, UUID는 랜덤이므로 성능 저하가 크게 발생 가능
InnoDB는 기본키(PK)의 B+Tree에 테이블 행을 저장한다.이를 클러스터형 인덱스(clustered index)라고 부른다. 클러스터형 인덱스는 기본키를 기준으로 자동으로 행의 순서를 지정한다. 그런데 무작위 UUID를 가진 행을 삽입하면 여러 문제가 발생할 수 있어 성능 저하를 초래한다. 이와 관련된 내용은 아래 참고자료를 살펴보자.
📝 참고자료
🚀 ULID
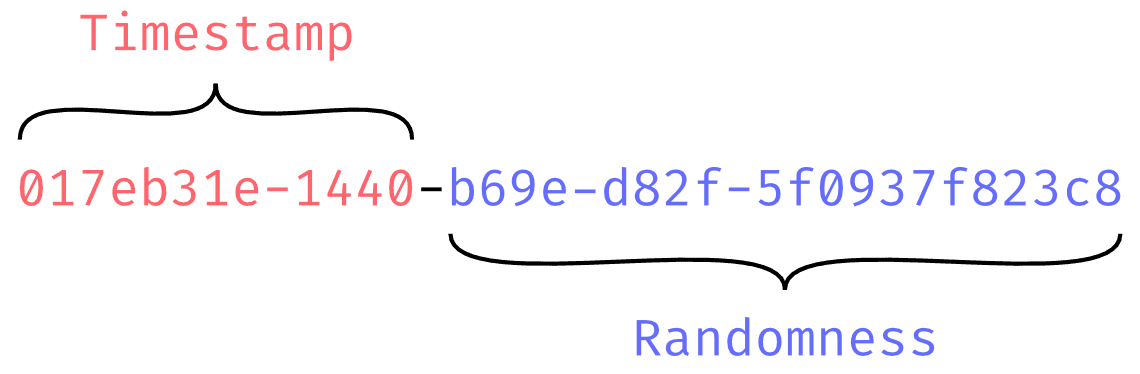
- UUID와 많이 유사하며, 128bit 용량을 가짐
- 앞의 Timestamp(타임스탬프)가 48bit 사용하므로 시간순 정렬 가능
- 기원시간인 Epoch(밀리초)로 시간을 인코딩
- 뒤의 Randomness(무작위성)은 80bit를 가짐
- 밀리초의 정밀도를 가지며, 단순하게 증가
- 밀리초 내에 동시 생성되면 무작위성에 따라 순서가 달라짐
👍 장점
- UUID의 단점을 해결하기 위해 만들어짐
- UUID의 36문자와 달리 ULID는 26문자로 인코딩됨
- UUID는 Base16, ULID는 Base32 문자 집합을 사용하기 때문에 ULID가 더 짧은 문자열을 가짐
- 특수 문자 없음 (URL 안전)
- 대소문자 구분하지 않음
- 시간순 정렬 가능
- 효율성과 가독성을 위해 Crockford의 Base 32 사용
- "I", "L", "O", "U" 제외됨
- 문자당 5bit
😈 단점
- 128bit로 상대적으로 용량이 큼
Base32는 Base16보다 더 많은 정보를 한 문자에 담을 수 있기 때문에 ULID가 문자열이 26자로 표현된다. Base16은 16진수로 표현된 데이터를 나타내며, 각 문자는 4비트를 나타낸다. 128bit(16byte)의 데이터를 Base16으로 표현하면 32자의 문자열이 필요하다. 반면에 Base32는 각 문자가 5비트의 정보를 표현하고, 128bit 데이터를 26자의 문자열만으로 표현할 수 있다.
💡 UUID는 Base16이므로 32문자로 표현할 수 있지만 특수문자인 하이픈(`-`)이 4개 추가되기 때문에 총 36문자이고, ULID는 특수문자가 없기 때문에 온전히 26문자로 표현이 가능하다. 이것이 UUID와 ULID를 구별짓는 중요한 차이 중 하나이다.
🚀 티켓 서버(ticket server)

- auto_increment 기능을 갖춘 DB를 중앙 집중형으로 하나만 사용하는 것
- 즉, 분산 환경에서 고유한 식별자를 생성하고 관리하기 위해 사용되는 중앙 집중식 서버를 의미
- 티켓 서버는 다양한 클라이언트나 서비스가 동시에 접근하여 고유한 티켓(식별자)를 얻을 수 있는 장소로 사용됨
👍 장점
- 유일성이 보장되는 숫자로만 구성된 ID를 쉽게 생성
- 구현하기 쉽고, 중소 규모 애플리케이션에 적합
😈 단점
- 티켓 서버가 SPOF(Single-Point-of-Failure, 단일장애지점)이 됨
- 티켓 서버 장애 발생 시, 해당 서버를 이용하는 모든 시스템이 영향을 받음
- 티켓 서버 여러 대 준비해야하는데 이러면 데이터 동기화 같은 새로운 문제 발생
- 확장하기 어려움
- 여러 서버에서 티켓 서버로 요청하므로 병목 현상 발생 가능
🚀 트위터 스노플레이크(snowflake) 접근법
트위터는 고가용성 방식으로 초당 수만 개의 ID를 생성할 수 있는 것이 필요했고, 이러한 ID는 대략적으로 정렬 가능해야 하며, 64bit의 용량을 가져야 한다. MySQL 기반 티켓 서버는 일종의 재 동기화 루틴을 구축해야 했고, 다양한 UUID는 128bit가 필요했다. 따라서 대략적으로 정렬된 64bit 용량을 가진 ID를 생성하기 위해 타임 스탬프(timestamp), 작업자 번호(worker number) 및 시퀀스 번호(sequence number)의 구성을 결정했다. 시퀀스 번호는 스레드별로 지정되며, 작업자 번호는 시작 시 Zookeeper를 통해 선택된다. [원문링크] [Github 링크]
- 트위터(twitter)가 OSS(Open Source System, 오픈소스)로 공개한 ID 생성기(generator)
- Time-base 한 ID (시간대별 정렬 가능하며, 의미를 가지는 ID)
- 확장 가능하며, 병렬로 유일성을 가진 ID 생성 가능
- 생성해야 하는 ID 구조를 여러 영역(section)으로 분할하여 사용

📚 스노우플레이크 구조 설명
- 사인(sign) 비트
- 1bit 할당
- 음수와 양수를 구별하는 데 사용
- 타임스탬프(timestamp)
- 41bit 할당
- 기원 시각(epoch) 이후로 몇 밀리초(millisecond)가 경과했는지 나타내는 값
- 41bit로 표현할 수 있는 타임스탬프 최댓값은 2^41 - 1 = 2199023255551ms
- 최댓값은 69년이므로 이 생성기는 69년동안 정상 작동
- 시간의 흐름에 따라 큰 값을 가지게 되므로 결국 ID는 시간순 정렬 가능.
- 데이터센터(datacentor) ID
- 5bit 할당
- 2^5 = 32개 데이터센터 지원 가능
- 서버(server) ID
- 5bit 할당
- 데이터센터당 32개 서버를 사용 가능
- 일련번호(sequence number)
- 12bit 할당
- 12bit이므로, 2^12 = 4096개의 값을 가질 수 있음
- 각 서버에서는 ID 생성할 때마다 이 일련번호를 1만큼 증가
- 일련번호는 1밀리초가 경과할 때마다 0으로 초기화(reset)
- 즉, 1밀리초 내에 두 개 이상의 ID를 생성하지 않는 한 이 영억은 일반적으로 0 이다
데이터센터ID와 서버ID는 시스템 시작 시 결정되며, 일반적으로 시스템 운영 중에는 바뀌지 않음.
타임스탬프나 일련번호는 ID 생성기가 돌고 있는 중에 만들어지는 값.
👍 장점
- 프로세스당 초당 최소 10,000개 ID 생성
- 응답 속도 2ms (네트워크 대기 시간 추가)
- 시계열(시간순, 날짜순) 정렬 가능
- UUID 128bit에 비해 64bit로 상대적으로 적으면서 많은 id 생성 가능
- 독립적으로 ID 생성 가능하므로 분산환경에서 확장성 높음
- 병렬로 유일한 ID 생성 가능
😈 단점
- 69년동안 사용가능함
- 중~소규모에서 운영할 때는 trade-off를 생각해야 함
- sequence 또는 auto_increment에 비해 용량이 크기때문에 비용이 상대적으로 높음
- 서비스가 폭풍성장한다면 DB구조변경, 데이터 마이그레이션, 동시성 문제같은 여러 비용을 생각한다면 미리 만드는것이 좋을수 있음
🚀 TSID(Time-Sorted Unique Identifier)
- twitter의 snowflake와 ULID Spec의 아이디어를 결합한 것
- 64bit 정수 생성 가능
- 문자열 형식은 Crockford의 base32로 저장
- 문자열은 URL 형식을 구분하지 않음
- UUID, ULID, KSUID보다 짧음
- 13자의 문자(13 chars)로 저장 가능

📚 TSID 구조
- 시간(Time component) 42bit 와 랜덤구성요소(Random component) 22bit 로 이루어짐
- 시간구성요소는 2020-01-01 00:00:00 UTC 이후의 밀리초 수
- 랜덤구성요소는 노드ID(node ID)의 0~20bit와 카운터(counter)의 2~22bit로 이루어짐
- e.g. 노드 비트가 10이면 카운터 비트는 12로 제한되는 것
- 시간구성요소는 부호 있는 64bit 정수 필드에 저장되면 약 69년 동안 사용 가능
- 시간구성요소는 부호 없는 64bit 정수 필드에 저장되면 약 139년 동안 사용 가능
👍 장점
- 64bit(8 byte)로 UUID에 비해 상대적으로 적은 용량
- DB에 bitint로 저장하고, Java에서 long 사용 가능
- UUID와 기존 정수 기반 ID 모두 활용 가능
- 기본키를 바이트 배열 대신 읽을 수 있는 정수(64bit)로 가져옴
- 시계열 정렬이 가능해서 DB 성능 저하가 발생하지 않음
- JPA와 Hibernate에서 구현되었기에 매우 간단하게 사용 가능
😈 단점
- 69년 또는 139년동안만 사용가능함
📝 참고자료
- DB의 기본키는 무엇을 사용해야 할까? ID와 UUID 외에 다른 것이 있을까?
- JPA 및 Hibernate를 사용하여 TSID 엔티티 식별자를 생성하는 가장 좋은 방법
- 데이터베이스 기본키에 가장 적합한 UUID 유형
👨🏫 JPA & Hibernate 엔티티에서 사용방법
Spring Boot 3 버전을 사용할 경우 Hibernate 6 버전을 사용한다.
따라서 아래 코드를 build.gradle의 dependencies(의존성)에 추가하자.
(아래 코드의 맨 마지막 버전은 자기 프로젝트 호환성에 맞게 고쳐도 됨)
implementation 'io.hypersistence:hypersistence-utils-hibernate-60:3.5.1'
위 라이브러리를 추가했다면 이제 `@Tsid` 어노테이션만 사용하면 아주 간단하게 구현이 되었다.
import io.hypersistence.utils.hibernate.id.Tsid;
import jakarta.persistence.Id;
public class TestEntity {
@Id @Tsid
private Long id;
private String title;
}
Hypersistence Utils 프로젝트는 Spring과 Hibernate 모두를 위한 범용 유틸리티를 제공하는데 여기에 TSID가 구현되어있기 때문이다. Hypersistence Utils 3.2 버전부터 시간정렬식별자(tsid)를 제공하고 있다.
이 외에도 Hibernate 5에서 사용하거나 TSID 값 생성기를 커스터마이징 하고 싶으면 이 글을 참고하자.
TSID 값만 생성하는 것이 필요하다면 TSID Github를 의존성 추가하여 사용하자.
🚀 결론
- 외부에 왠만하면 추측가능한 ID를 노출하지 않는게 좋음 (엔티티를 외부에 노출하지 않듯이)
- e.g. "/users/109" 보다는 "/users/38352658568129975" 또는 "/users/01294A2BDA2"
- 외부 노출용 ID를 따로 생성해서 내부 pk와 키-값으로 연결하여 주고받거나, 내부 pk를 암호화하는 방법도 있음
- "이게 제일 좋다!" 라는 것은 없고 상황마다 적절한 것을 trade-off 하여 사용하여야함
- e.g. 내부적으로 사용하는 것이라면 굳이 PK를 UUID, TSID로 사용할 필요 없이 auto_increment 사용
- e.g. 숫자는 문자열에 비해 작은 크기를 가지므로 저장 및 검색 속도에서 좋고, 문자열은 복잡하게 구성 가능
- 분산환경에서는 UUID의 단점을 개선한 TSID, snowflake 를 사용하는 것이 좋음
- 각 서버가 독립적으로 유일성이 보장된 ID를 생성할 수 있기 때문
- DB가 2대 이상 확장될 수 있는 가능성이 있다면 auto_increment보단 TSID, snowflake이 좋음