데브코스-데이터엔지니어링
Python - Web Scraping 기초 (BeautifulSoup4 라이브러리)
묠니르묘묘
2024. 4. 3. 22:26
BeautifulSoup4 라이브러리
- HTML 코드를 분석해주는 HTML Parser 사용 가능
# pip를 사용해 라이브러리 설치
%pip install bs4
# 사이트에 요청한 후 응답 받기
import requests
res = requests.get("http://www.example.com")
# BeautifulSoup4 - bs4 불러오기
from bs4 import BeautifulSoup
# BeautifulSoup 객체 생성하기.
# 첫번째 인자는 response의 body를 텍스트
# 두번째 인자는 "html"로 분석한다는 것을 명시
soup = BeautifulSoup(res.text, "html.parser")
# 객체 soup의 .prettify()를 활용하여 분석된 HTML을 보기 편하게 반환하기
print(soup.prettify())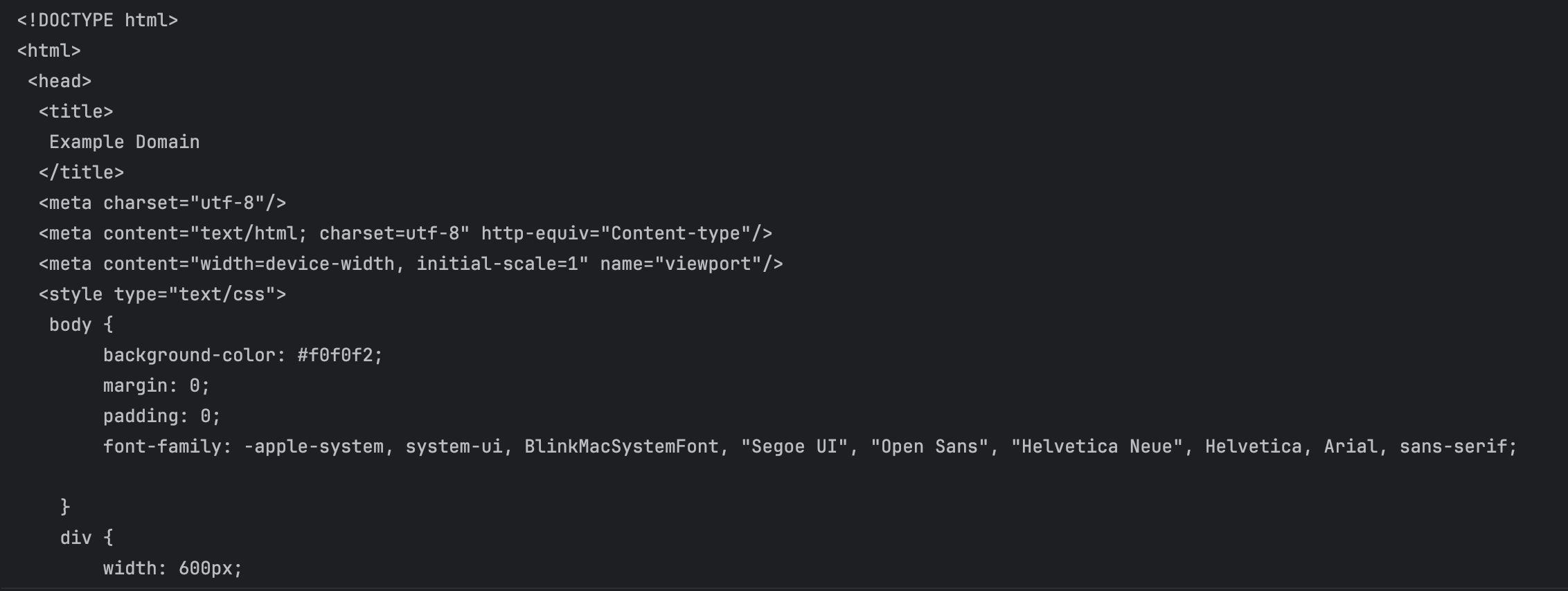
이제 위 코드의 soup로 조작하여 HTML에 쉽게 접근할 수 있다.
# title 가져오기
soup.title
# head 가져오기
soup.head
# body 가져오기
soup.body
# <h1> 태그로 감싸진 요소 찾기
h1 = soup.find("h1")
# 태그 이름 가져오기
h1.name
# 태그 내용 가져오기
h1.text
# <h3> 태그로 감싸진 모든 요소 찾기
h3_result = soup.find_all("h3")
# <h3> 태그로 감싸진 모든 요소의 내용 추출하기
for t in h3_result:
print(t.text)
# id가 results인 div 태그 찾기
soup.find("div", id="results")
# class가 "page-header"인 div 태그 찾기
find_result = soup.find("div", "page-header")
# Pagination이 되어있는 hashcode 질문 리스트의 제목을 모두 가져오기
# 과도한 요청 방지로 1초마다 요청을 보냄
import time
for i in range(1, 6):
res = requests.get("https://hashcode.co.kr/?page={}".format(i), user_agent)
soup = BeautifulSoup(res.text, "html.parser")
questions = soup.find_all("li", "question-list-item")
for question in questions:
print(question.find("div", "question").find("div", "top").h4.text)
time.sleep(0.5)