빅데이터의 파일 형식은 무엇으로 해야할까? (feat. Parquet 란?)
데이터 엔지니어 프로젝트를 진행하면서 컬럼이 수십개에 레코드는 수십만개의 데이터를 다루면서 데이터 유형에 대해 고민하게 되었다. 단순히 보기 편하고 다루기 쉬운 행 기반 형식의 CSV 파일만을 생각했는데 읽고 쓰는 I/O 성능이 느려서 새로운 파일 유형을 찾게 되었다. 그것이 parquet 같은 빅데이터 파일 형식이다.
1. 고민해야할 점
- 데이터가 기하급수적으로 증가함에 따라 효율적인 데이터 저장방법은 무엇일까?
- 데이터를 행과 열로 구성하는 것의 차이점과 이것이 저장 및 쿼리 효율성에 어떤 영향을 미칠까?
- 행 기반 형식으로 데이터를 저장하는 것의 장단점과 쓰기 작업이 많은 작업에 대한 적합성은 무엇일까?
- 빠른 쿼리 속도와 효율적인 압축 옵션 등 읽기 작업이 많은 작업을 위한 열(컬럼) 기반 저장소의 이점은?
- Parquet와 ORC 파일 형식의 차이점과 각 형식의 최적 사용 사례가 무엇일까?
2. Parquet 파일 형식이란?
- 빠른 분석 쿼리를 위한 무료 오픈소스 스토리지 형식
- 효율적인 데이터 압축 및 인코딩 체계를 제공
- 복잡한 쿼리 실행하고 대용량 데이터를 처리하는데 이상적인 파일 형식
- Announcing Amazon Redshift data lake export 에서 "Parquet 형식은 텍스트 형식에 비해 UNLOAD 속도가 최대 2배 빠르고, AWS S3 에서 스토리지 사용량이 최대 6배 적습니다" 라고 설명함
- 또한, 하나 이상의 파티션 열을 지정하여 언로드된 데이터를 S3 버킷 폴더로 자동 분할 가능
- e.g. 연도, 월, 일 별로 분할하도록 선택 가능
- 파티션 잘라내기 기능과 관련없는 파티션 검색 건너뛰기 기능 활용하여 쿼리 성능 개선 및 비용 최소화 가능
- 또한, 하나 이상의 파티션 열을 지정하여 언로드된 데이터를 S3 버킷 폴더로 자동 분할 가능
- 데이터를 Parquet 또는 ORC 같은 열 형식으로 변환하는 것도 AWS Athena 성능 개선하는 수단으로 권장
- 필요한 블록만 fetch 하여 쿼리 성능 개선
- Apache Parquet 는 Data Lake 사용할 때 시스템 성능에 중요한 역할을 함
3. Parquet vs. ORC (Optimized Row Columnar)
Parquet 와 ORC 는 빅데이터 애플리케이션에 적합한 선택이기에 요구사항을 고려하여 적합한 형식을 선택하자.
쿼리 성능 (Queery Performance)
- parquet가 더 광범위하고 복잡한 쿼리 유형 지원
복합 데이터 유형 (Complex Data Types)
- ORC 가 더 광범위한 복합 데이터 유형 지원
쓰기 효율성 (Write Efficiency)
- ORC 는 Hive에서 ACID 트랜잭션 지원하므로 쓰기 작업이 많을 경우 선택
- Parquet는 일반적으로 분석 작업 부하와 크고 복잡한 데이터 구조 작업할 때 좋음
- ORC 는 쓰기 작업과 데이터 수정이 필요할 때 더 이상적이며, Parquet에 비해 더 나은 쓰기 속도 제공
읽기 효율성 (Read Efficiency)
- Parquet 는 한 번 쓰고 여러 번 읽는 분석 시나리오에서 탁월하며, 매우 효율적인 데이터 압축 및 압축 해제 제공
- Parquet 는 데이터 건너뛰기를 지원하며, 쿼리 전체 데이터 행을 건너뛰면서 특정 열 값 반환이 가능하므로 I/O 최소화
- 데이터 세트에 많은 수의 컬럼이 있고, 특정 데이터 하위 집합에만 접근해야 하는 시나리오에서 ORC 가 유용할 수 있음
호환성 (Compatibility)
- ORC 는 Hive 생태계와 호환되며 Apache Hive 와 함께 작업 시, ACID 트랜잭션 지원
- Parquet는 Java, Python, C++ 같은 여러 프로그래밍 언어 지원하며 거의 모든 빅데이터 설정에서 사용할 수 있도록 광범위한 접근성 제공하며, AWS Athena, AWS Redshift Spectrum, Qubole, Google BigQuery 등 여러 쿼리 엔진에서 사용됨
파일 크기 (File Size)
- 디스크 공간이 문제인 경우, ORC 는 일반적으로 더 작은 파일을 생성하여 저장 비용 줄임
압축 (Compression)
- 둘 다 우수한 압축 제공하기에 적합한 형식은 특정 사용 사례에 따라 다름
- 그러나 압축이 주요 기준이면 Parquet 를 선택함. 이는 매우 효율적인 압축 및 인코딩 체계로 더 작은 파일 크기를 제공하기 때문이며 컬럼별로 특정 압축 체계를 지원하여 저장된 데이터를 더욱 최적화 가능하기 때문임
진화 (Evolution)
- 둘 다 스키마 진화(Schema Evolution) 지원
- 즉, 시간이 지남에 따라 열(column) 추가, 제거 및 수정 가능
Parquet와 다른 파일 형식 비교를 보려면 Parquet, ORC, and Avro: The File Format Fundamentals of Bic Data 를 살펴보자.
4. Parquet 특징

- 열 기반 (Columnar)
- CSV 또는 Avro 같은 행 기반 형식과 달리 열 기반
- 즉, 각 레코드 값이 아닌 각 테이블 열의 값이 나란히 저장
- 오픈소스 (Open-source)
- Parquet 는 Apache Hadoop 라이센스에 따라 무료 사용 가능한 오픈소스
- 대부분의 Hadoop 데이터 처리 프레임워크와 호환
- 자체 설명 (Self-describing)
- Parquet 파일에는 데이터 외에도 스키마와 구조를 포함한 메타 데이터 포함
- 각 파일은 데이터와 각 레코드에 액세스하는 데 사용되는 표준을 모두 저장하므로 Parquet 파일을 쓰고, 저장하고, 읽는 서비스를 쉽게 분리 가능
- 각 파일은 각 레코드에 액세스하는 데 사용되는 데이터와 표준을 모두 저장하므로 Parquet 파일을 쓰고, 저장하고, 읽는 서비스를 분리하기가 더 쉬움
- 데이터 타입도 메타데이터에 저장되기에 CSV 와 달리 따로 데이터 유형을 명시하지 않아도 됨
5. Parquet 장점
5-1. 압축 (Compression)
- Parquet 에서 압축은 열 단위로 수행되며 데이터 유형별로 유연한 압축 옵션과 확장 가능한 인코딩 스키마를 지원하도록 구축됨
- e.g. 정수 및 문자열 데이터를 압축하는 데 서로 다른 인코딩 사용
- 사전 인코딩 (Dictionary Encoding)
- 고유 값이 적은 데이터에 대해 자동으로 동적 활성화
- 반복되는 값을 고유한 코드로 매핑하여 저장하는 방식이며, 반복되는 값이 많은 열에서 효과적
- 고유 값이 많을 경우에는 사전 크기가 커지면서 오히려 메모리 사용량이 늘어날 수 있음
- 비트 패킹 (Bit Packing)
- 정수 저장은 일반적으로 정수당 전용 32bit 또는 64bit로 이루어짐
- 이를 통해 작은 정수를 보다 효율적으로 저장
- 실행 길이 인코딩 (RLE, Run Length Encoding)
- 동일한 값이 여러 번 발생하면 발생 횟수에 따라 하나의 값이 한 번씩 저장됨
- Parquet 는 비트 패킹과 RLE 의 결합 버전을 구현하며, 어떤 인코딩이 최상의 압축 결과를 생성하는지에 따라 인코딩이 전환됨
5-2. 성능 (Performance)
- CSV 와 같은 행 기반 파일과 달리 Parquet 는 성능을 위해 최적화 됨
- 파일 시스템에서 쿼리 실행 시, 매우 빠르게 관련 데이터에만 집중 가능
- 스캔되는 데이터 양이 훨씬 적어 I/O 사용량 최소화
5-3. 스키마 진화 (Schema evolution)
- Parquet 와 같은 열 형식의 파일 사용하는 경우, 사용자는 간단한 스키마로 시작하여 필요에 따라 점차적으로 스키마에 열(컬럼) 추가 가능
- 이러한 방식으로 사용자는 서로 다르지만 상호 호환되는 스키마를 가진 여러 개의 Parquet 파일을 가질 수 있음
- 이러한 경우 Parquet 는 이러한 파일 간의 자동 스키마 병합을 지원함
5-4. 오픈소스 및 비독점적 (Open source and non-proprietary)
- Apache Parquet 는 오픈소스 Apache Hadoop 생태계 일부
- 활발하게 개발 진행 중이며 사용자 및 개발자 커뮤니티에 의해 지속적으로 개선 및 유지관리
- 데이터를 오픈 포맷으로 저장하면 공급업체에 묶이지 않고 유연성 높일 수 있음
- 많은 최신 고성능 DB에서 사용하는 독점 파일 포맷과 비교 가능
- 즉, 특정 DB 공급업체에 묶이지 않고도 동일한 데이터 레이크 아키텍처 내에서 AWS Athena, AWS Redshift, Qubole 과 같은 다양한 쿼리 엔진 사용 가능
6. Parquet 구조
- 자체 설명 형식으로 각 파일에는 데이터와 메타데이터 모두 포함
- 파일은 행 그룹(row groups), 헤더(header) 및 푸터(footer)로 구성
- 각 행 그룹에는 동일한 열 데이터 포함
- 동일한 열은 각 행 그룹에 함께 저장
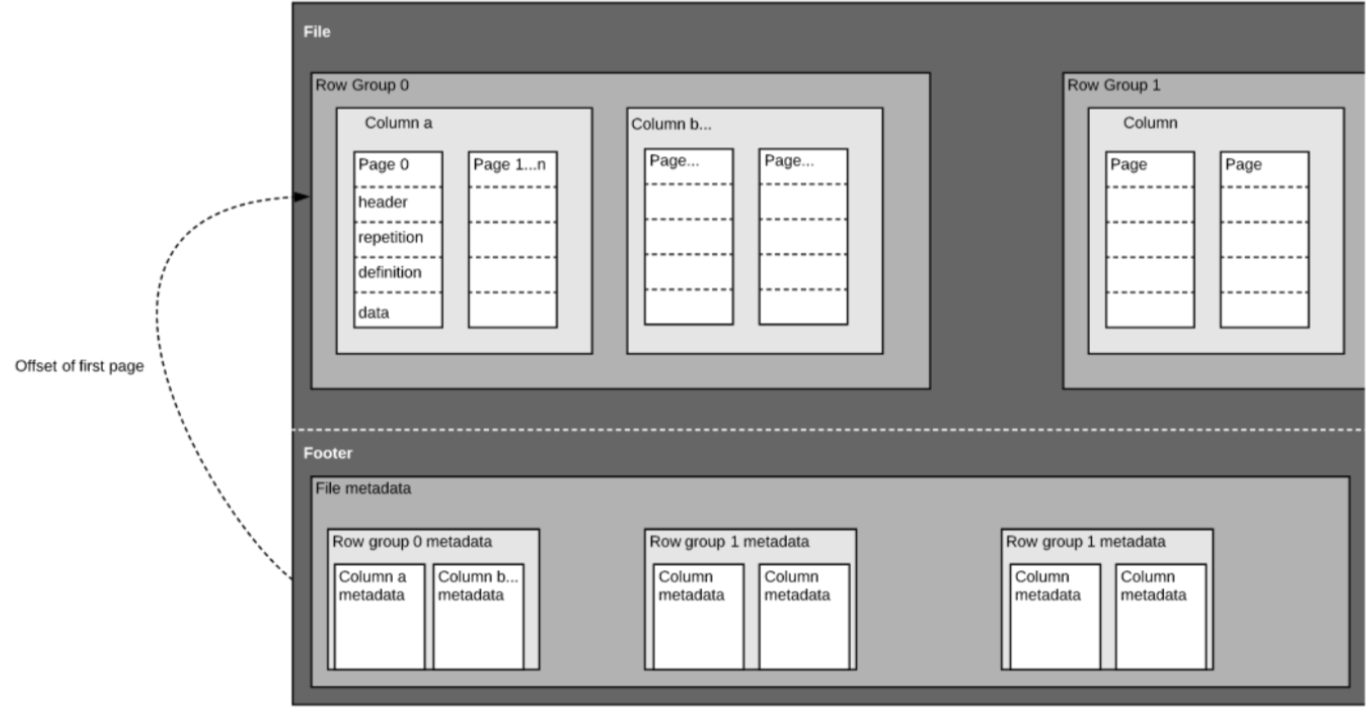
- 이 구조는 빠른 쿼리 성능과 낮은 I/O (스캔되는 데이터 양 최소화)를 위해 최적화 되어 있음
- e.g. 열이 1000개인 테이블이 있는데 일반적으로 열의 작은 하위 집합만 사용하여 쿼리한다고 가정한다면
- Parquet 파일을 사용하면 필요한 열과 해당 값만 가져와서 메모리에 로드하고 쿼리 응답 가능
- CSV 와 같은 행 기반 파일의 경우에는 전체 테이블을 메모리에 로드해야 하므로 I/O 증가 및 성능 저하
- e.g. 열이 1000개인 테이블이 있는데 일반적으로 열의 작은 하위 집합만 사용하여 쿼리한다고 가정한다면
7. 분석 쿼리를 위한 열 기반 스토리지 vs. 행 기반 스토리지
(Column-Oriented vs. Row-Based Storage for Analytic Querying)
데이터는 종종 행으로 생성되고 쉽게 개념화 된다. 우리는 엑셀(Excel) 스프레드 시트 관점에서 생각하는 것이 익숙하며, 특정 레코드와 관련된 모든 데이터를 깔끔하고 체계적으로 정리된 한 행에서 볼 수 있다. 그러나 대규모 분석 쿼리의 경우 열 기반 스토리지는 비용과 성능 측면에서 상당한 이점이 있다.
Logs and Event Streams 와 같은 복잡한 데이터는 수백 또는 수천 개의 컬럼과 수백만 개의 행이 있는 표로 표현된다. 이 표를 CSV 같은 행 기반 형식으로 저장하면 아래와 같다.
- 쿼리에 대한 결과에 필요한 열의 하위 집합만 쿼리하는 것이 아니라 더 많은 데이터를 스캔해야 하므로 쿼리 실행 시간이 더 오래 걸림
- CSV 는 Parquet 만큼 효율적으로 압축되지 않기에 스토리지 비용이 더 많이 듦
열 형식은 더 나은 압축률과 향상된 성능을 기본적으로 제공하며 데이터를 열 단위로 수직으로 쿼리 가능하다.
8. Apache Parquet 는 언제 사용해야 할까?
매우 많은 양의 데이터로 작업할 때
- Parquet 는 성능과 효과적인 압축을 위해 만들어짐
- 여러 벤치마킹 테스트에서 Parquet의 SQL 쿼리 실행 시간과 Avro 또는 CSV 같은 형식과 비교한 결과 Parquet 쿼리가 훨씬 더 빠르게 수행되는 것을 알 수 있음
전체 데이터 집합에 많은 열이 있지만 하위 집합에만 액세스해야 하는 경우
- 기록하는 비즈니스 데이터가 점점 더 복잡해지면서 각 데이터 이벤트에 대해 20개의 필드를 수집하는 대신 100개 이상의 필드를 수집하고 있을 수 있음
- 이러한 데이터는 데이터 레이크에 저장하기는 쉽지만, 행 기반 형식으로 저장된 경우 쿼리하려면 상당한 양의 데이터를 스캔해야 함.
- Parquet 의 열 형식과 자체 설명 기능을 사용하면 특정 쿼리에 응답하는 데 필요한 필수 컬럼만 가져올 수 있으므로 처리되는 데이터의 양을 줄일 수 있음
여러 서비스가 객체 저장소에서 동일한 데이터를 사용하도록 하려는 경우
- Oracle 또는 Snowflake 와 같은 데이터베이스 공급업체는 자사 도구만 읽을 수 있는 독점 형식으로 데이터를 저장하는 것을 선호하지만, 최신 데이터 아키텍처는 스토리지와 컴퓨팅을 분리하는 쪽으로 편향되어 있음
- 여러 분석 서비스를 사용하여 다양한 사용 사례에 대한 답을 찾으려면 데이터를 Parquet에 저장해야 함 (Read more about data pipeline architecture)
9. AWS 와의 호환성
- Redshift 쿼리 결과를 분석을 위한 효율적인 개방형 열 기반 스토리지인 Apache Parquet로 AWS S3 데이터 레이크에 UNLOAD(언로드) 가능
- Redshift 쿼리 결과를 parquet 파일로 S3에 저장 가능
- 하나 이상의 파티션 열을 지정하여 언로드 된 데이터를 S3 폴더로 자동 분할 가능
- 연도, 월, 일별로 분할하도록 선택 가능
- 컬럼형 parquet 스토리지는 분석 쿼리에 매우 효율적이며, AWS Athena 또는 AWS Redshift Spectrum과 같은 다양한 서비스에서 액세스 가능
10. AWS Redshift에서 대용량 데이터를 AWS S3에 CSV와 Parquet 파일로 저장하기
Redshift 쿼리편집기에 들어가서 진행함.
naver_real_estate 테이블에는 약 42만건의 데이터와 약 50개의 컬럼이 있음.
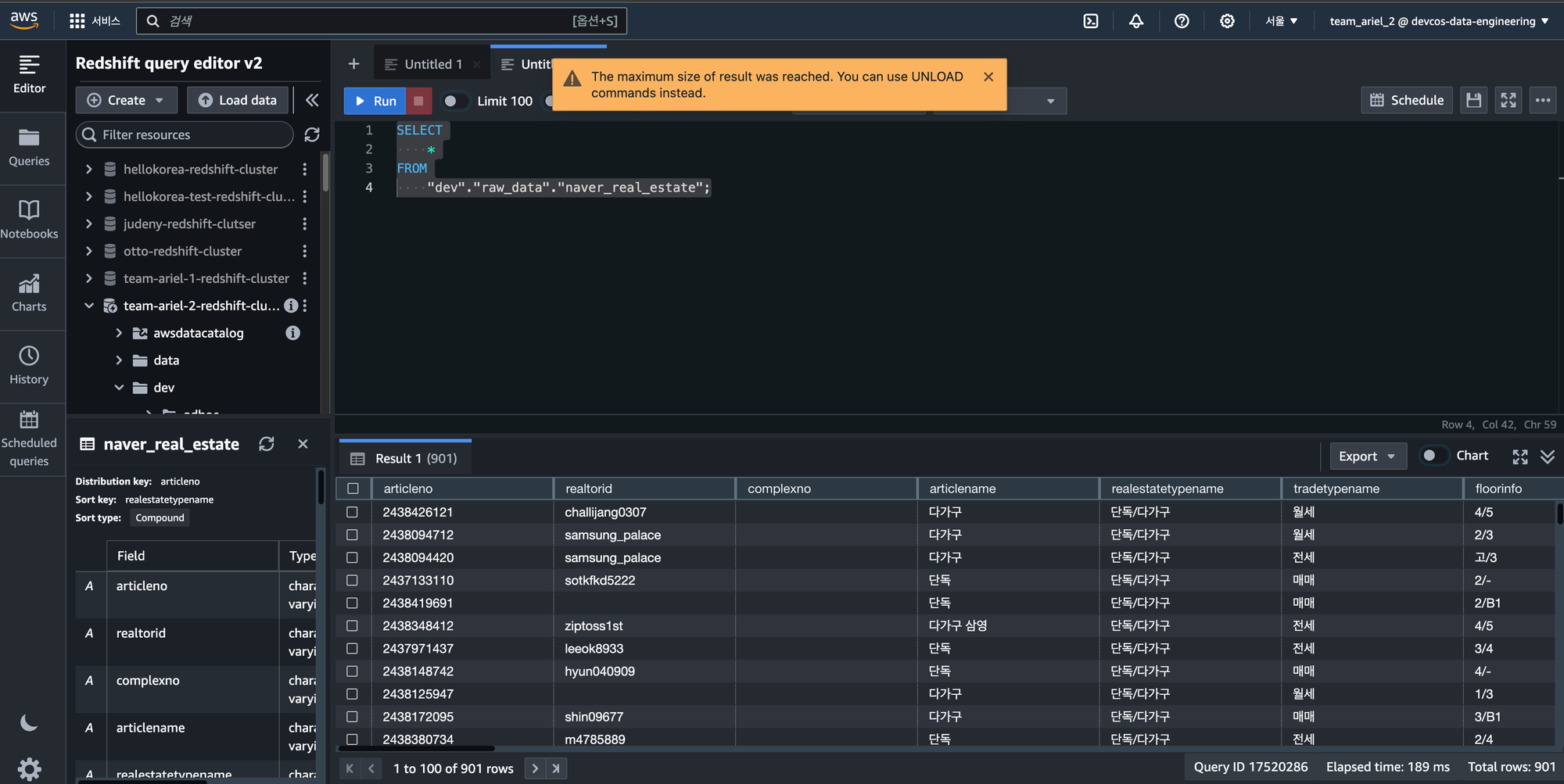
단순하게 전체 SELECT(조회) 하는데 데이터가 너무 커서 UNLOAD 명령어를 사용하라고 나온다.
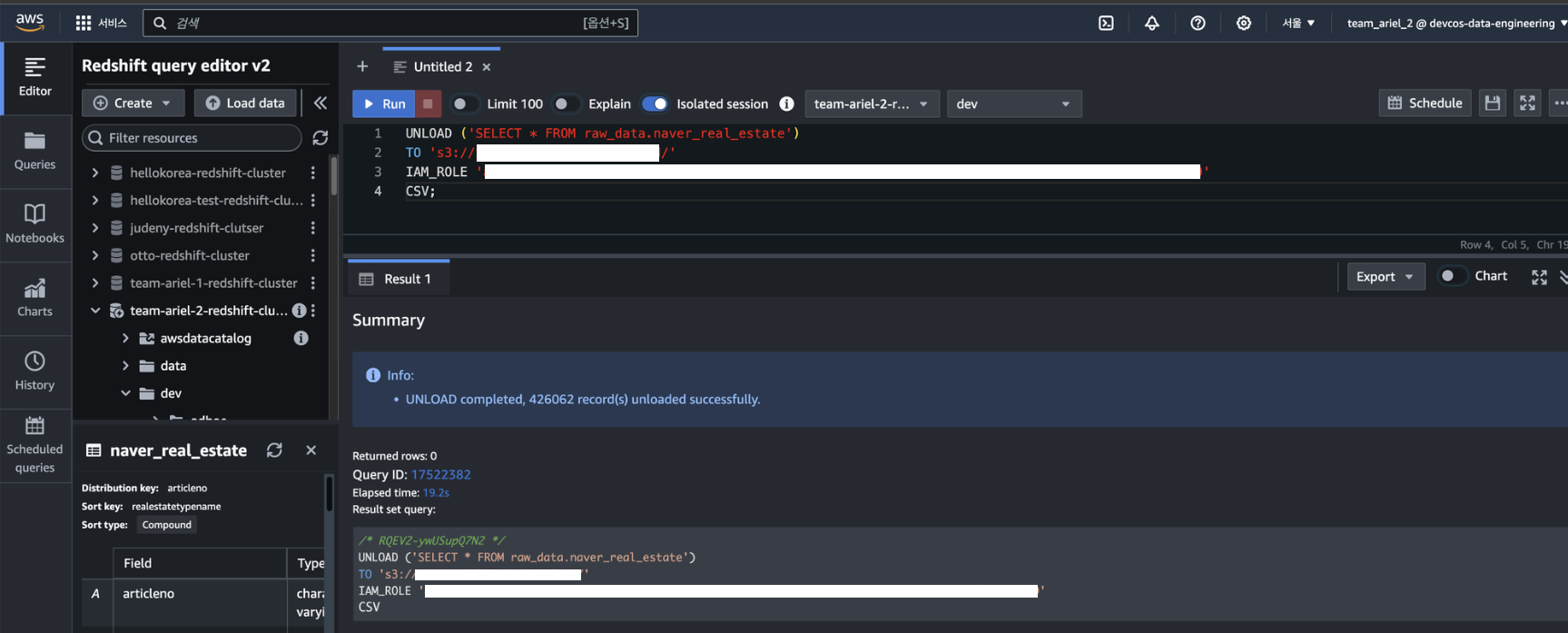
UNLOAD ('SELECT * FROM raw_data.naver_real_estate')
TO 's3://S3버킷이름'
IAM_ROLE 'IAM ROLE 입력'
CSV;42만건을 UNLOAD 명령어로 S3에 CSV 파일로 저장하는데 19.2초 소요됐다.
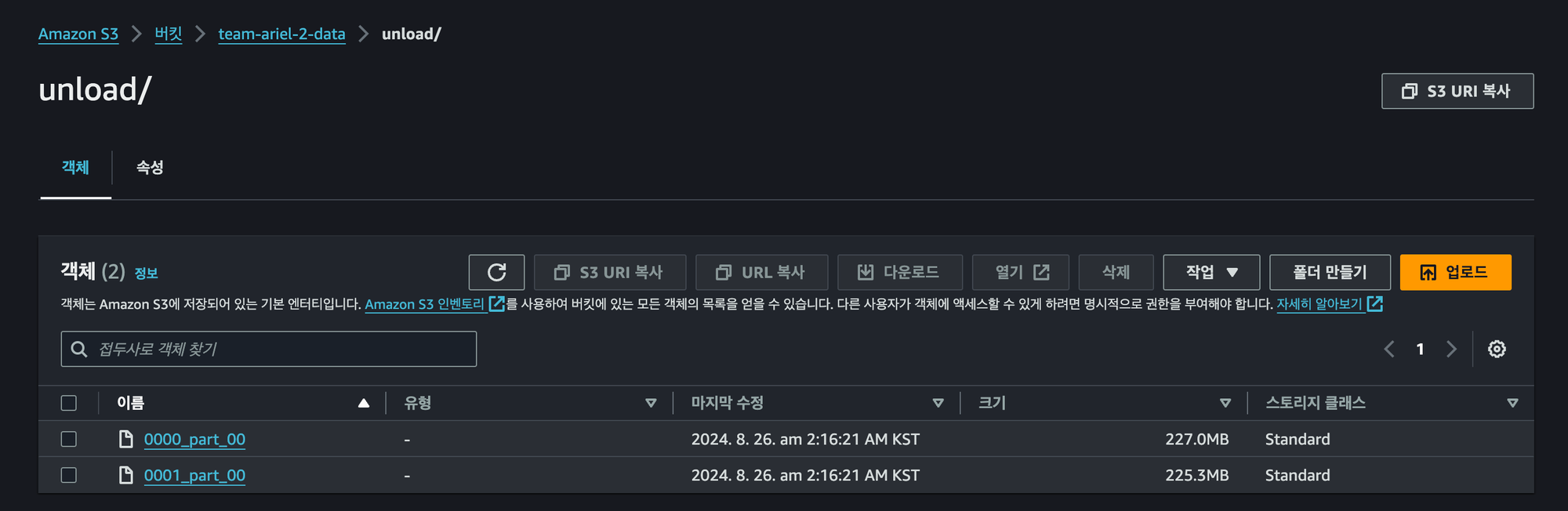
이 때 적절한 크기로 분할되는데 단일 파일로 저장하려면 PARALLEL OFF 명령어를 붙이면 된다.
또한, Redshift 명령어로 생성된 출력 파일 크기 제한은 UNLOAD의 경우 6.2GB 정도이다.
gzip 명령어도 사용하면 압축되기에 용량이 더욱 작아진다.
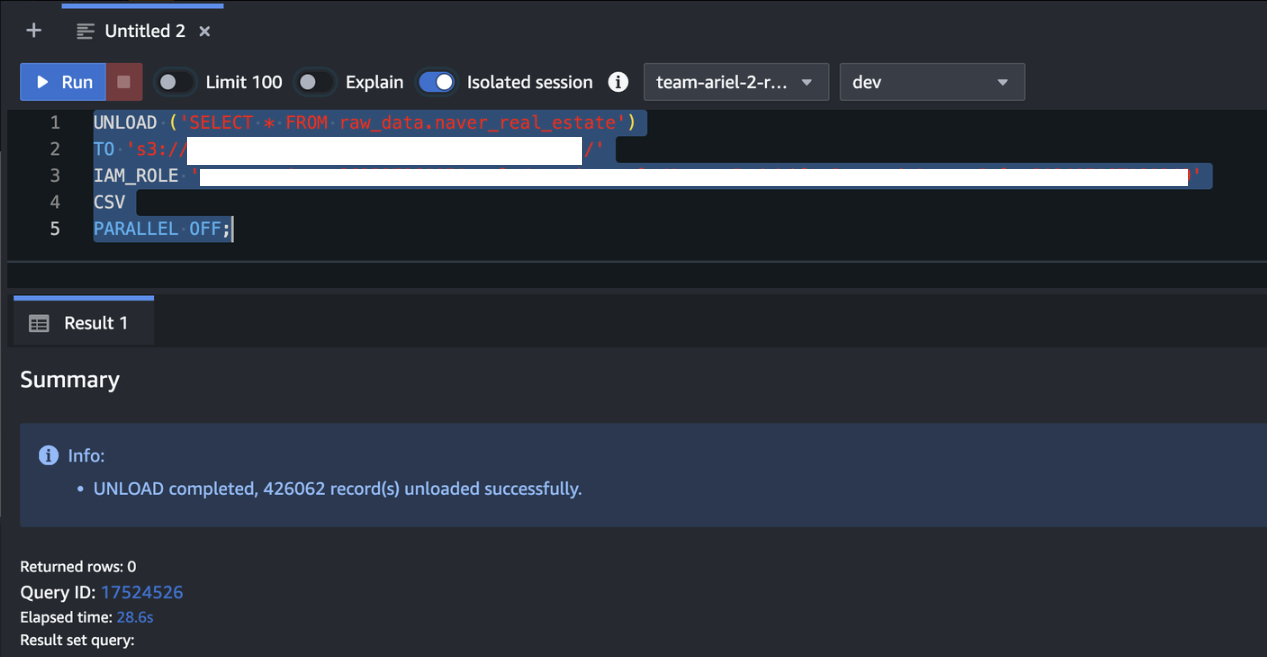
UNLOAD ('SELECT * FROM raw_data.naver_real_estate')
TO 's3://S3버킷명'
IAM_ROLE 'IAM ROLE 값'
CSV
PARALLEL OFF;파일을 분할하지 않으니 28.6초가 소요되며 파일 크기도 합쳐진 452MB가 생성된다.
UNLOAD ('SELECT * FROM raw_data.naver_real_estate')
TO 's3://S3버킷명'
IAM_ROLE 'iam role 값'
CSV
PARALLEL OFF
gzip;
단일 파일에서 gzip으로 압축하면 22.7초가 소요됐으며 용량은 452MB에서 132MB로 1/3으로 줄었다.
압축파일을 풀면 CSV 파일이 나온다.
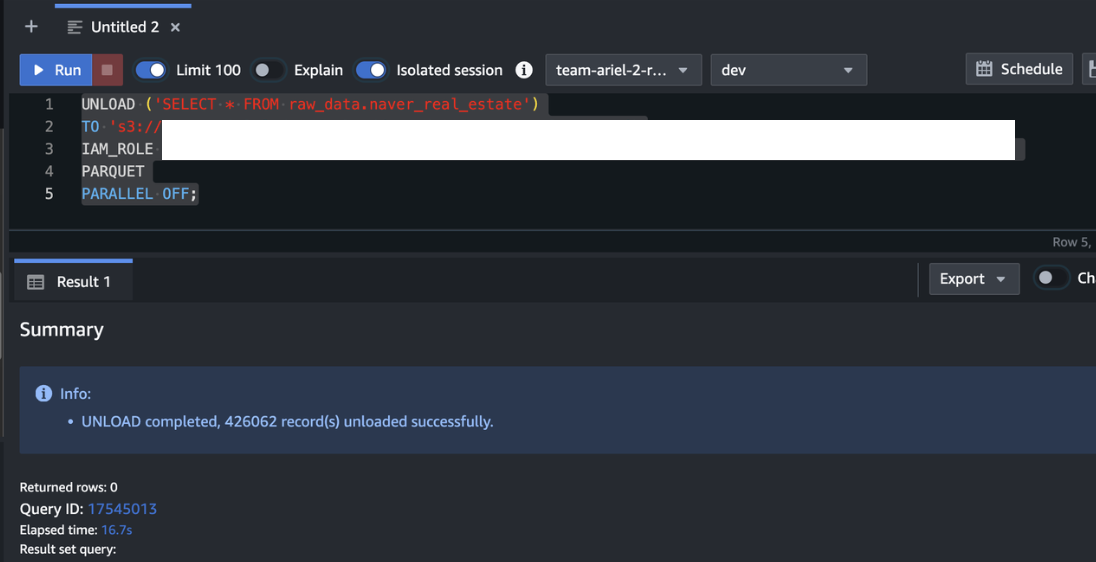
UNLOAD ('SELECT * FROM raw_data.naver_real_estate')
TO 's3://S3버킷명'
IAM_ROLE 'iam role 값'
PARQUET
PARALLEL OFF;
이번에는 Parquet 파일로 저장해보니 16.7초가 소요되며 CSV 파일을 압축한 것과 비슷한 용량으로 나오는 것을 알 수 있다.
11. Airflow DAG를 통해서 원하는 스키마의 모든 테이블을 S3에 저장하기
dev 데이터베이스에서 raw_data 스키마와 analytics 스키마 안에 있는 모든 테이블을 Parquet로 저장하는 코드를 작성해본다.
@task
def unload():
conn = get_redshift_connection()
cur = conn.cursor()
cur.execute("SHOW TABLES FROM SCHEMA dev.raw_data;")
tables = cur.fetchall()
for table in tables:
table_name = table[2]
unload_to_s3_parquet('raw_data', table_name, f's3://{BUCKET_NAME}/unload/raw_data/{table_name}/')
cur.execute("SHOW TABLES FROM SCHEMA dev.analytics;")
tables = cur.fetchall()
for table in tables:
table_name = table[2]
unload_to_s3_parquet('analytics', table_name, f's3://{BUCKET_NAME}/unload/analytics/{table_name}/')def unload_to_s3_parquet(schema: str, table: str, s3_path: str, parallel: bool = False):
iam_role = Variable.get("aws_iam_role")
conn = None
cur = None
try:
conn = get_redshift_connection()
cur = conn.cursor()
parallel_option = 'ON' if parallel else 'OFF'
cur.execute(f"""
UNLOAD ('SELECT * FROM {schema}.{table}')
TO '{s3_path}'
IAM_ROLE '{iam_role}'
PARQUET
PARALLEL {parallel_option};
""")
logging.info(f"SUCCESS AWS Redshift unloaded {schema}.{table} to {s3_path} as Parquet")
except Exception as e:
logging.error(f"Error Failed to UNLOAD {schema}.{table} to {s3_path}: {e}")
raise
finally:
if cur is not None:
cur.close()
if conn is not None:
conn.close()
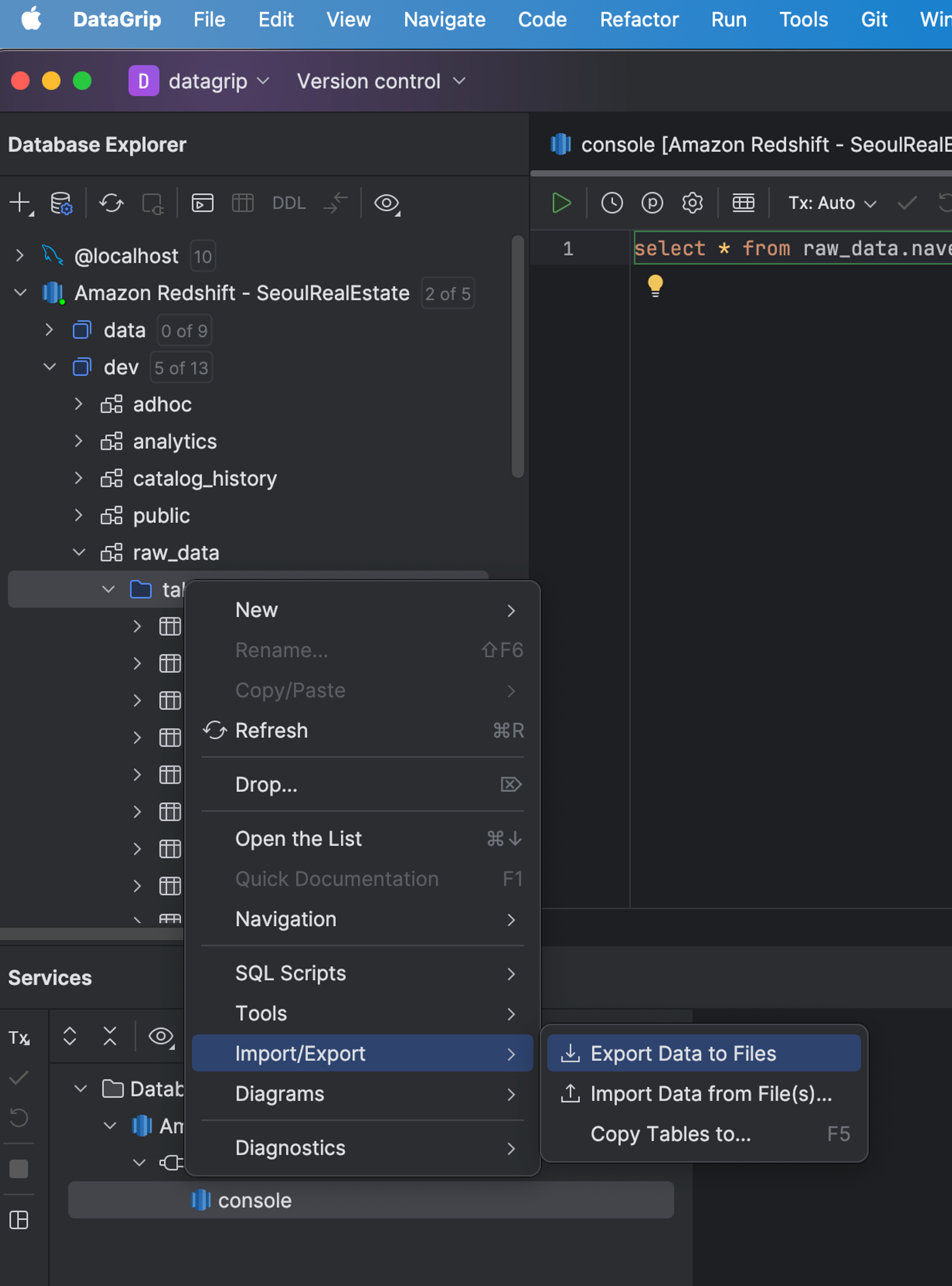
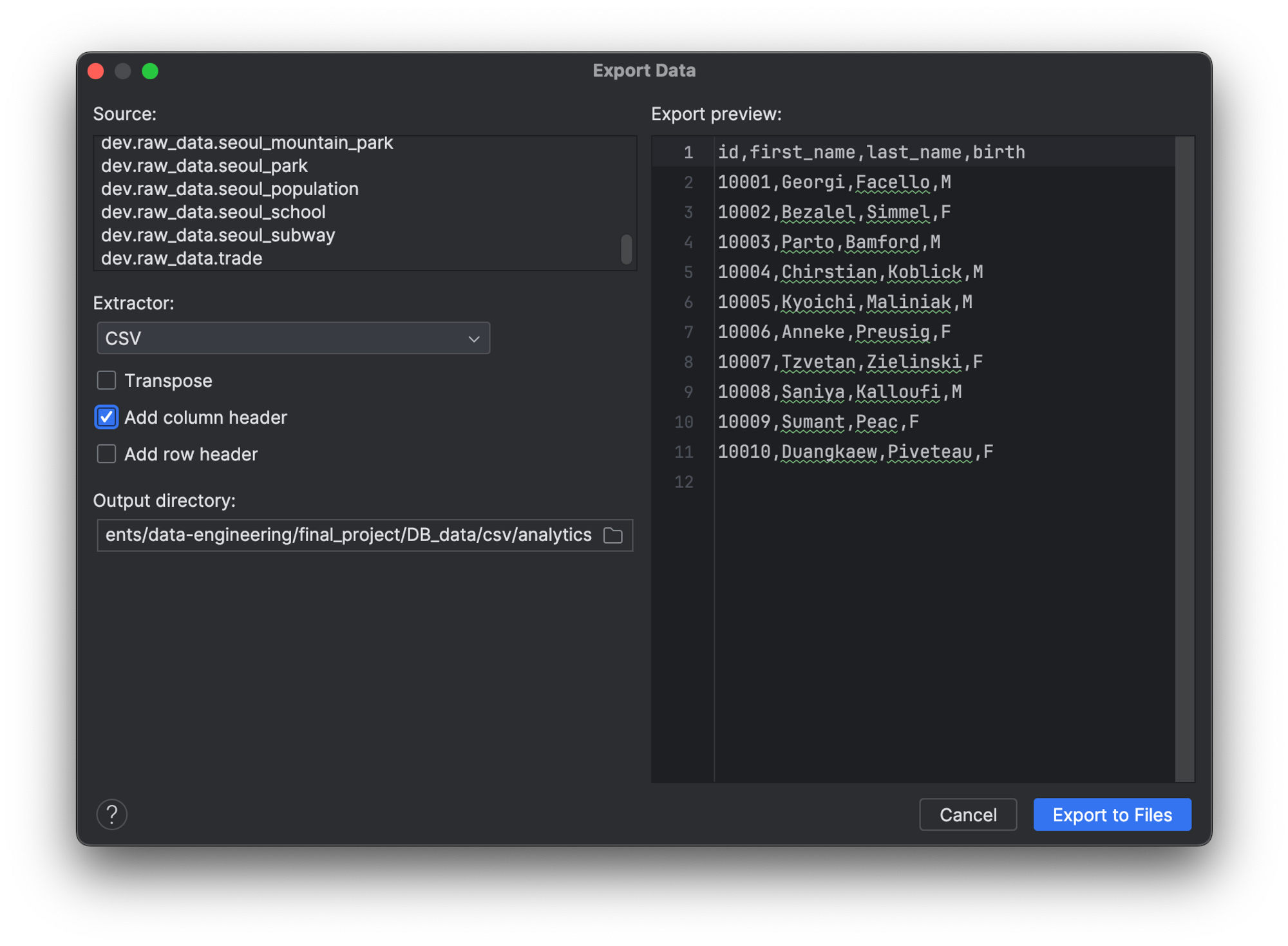
12. SQL DB 툴 (DataGrip)로 CSV파일 저장하기
데이터베이스 관리도구를 통해서도 테이블을 쉽게 다운로드 할 수 있다.
인텔리제이(IntelliJ)의 DB 툴인 DataGrip 에서도 아래와 같이 간단하게 파일로 저장할 수 있다.
이 때 Parquet 파일 형식은 없고 CSV로는 가능하다.
하지만 CSV 파일 저장 할 때 데이터 양이 많으면 제대로 다운로드가 안되며, 대략 400MB부터 안된다.
이 때 JVM 메모리를 더 높이라고 나오는데 아무래도 자체 메모리 부족으로 안되는 듯 하다.