
스프링 데이터 JPA란?
스프링 프레임워크에서 JPA를 편리하게 사용할 수 있도록 지원하는 프로젝트이다.
반복되는 CRUD 문제를 편하게 처리해준다.
인터페이스만 작성하면 실행 시점에 스프링 데이터 JPA가 구현 객체를 동적으로 생성해서 주입해준다.
따라서 구현클래스 없이 인터페이스만 작성해도 개발이 된다.
순수 JPA 기반 Repository 를 살펴보자.
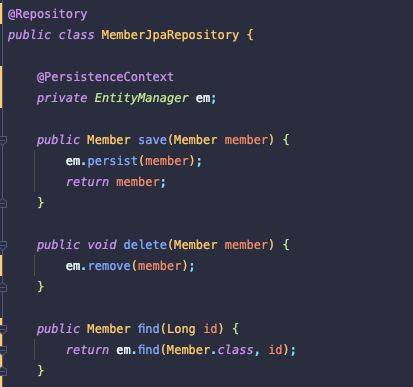
순수 JPA 기반 Repository를 써서 데이터 계층에 접근하려면 위와 같이 클래스에 @Repository 를 써야한다.
그러면 컴포넌트 스캔 대상이되서 스프링 빈에 등록을 해주므로 다른 클래스에서 사용할 수 있다.
@PersistenceContext로 스프링 컨테이너가 엔티티 매니저를 가져와준다.
엔티티 매니저를 통해 JPA를 사용할 수 있다.
그 밑으로는 save(저장), delete(삭제), find(조회) 가 있다.
수정은 JPA에서 dirty checking(변경감지) 기능을 사용하므로 트랜잭션 안에서 엔티티를 조회한 다음 데이터 변경 시 트랜잭션 종료 시점에 변경된 엔티티를 감지하고 UPDATE SQL을 실행시킨다.
이런 식으로 데이터 접근 계층에 대한 메서드를 만들어서 사용한다.

아까전에ember에 대한 데이터 접근 메서드를 만들었는데 이번에는 Team에 관한 것이다.
아까랑 똑같은 작업들이 있다.
이렇게 기본적은 CRUD라든지 비슷한 동작을 계속 만들어야하는데 이런 작업들을 스프링 데이터 JPA가 줄여준다.
스프링 데이터 프로젝트란??
아까 스프링 데이터 JPA는 JPA를 편리하게 도와주는 프로젝트라고 했다.
즉, 스프링 데이터 프로젝트의 하위 프로젝트 중 하나라는 뜻이다.
이 스프링 데이터 프로젝트의 하위 프로젝트에는 JPA, 몽고DB, REDIS 등 다양한 데이터 저장소에 대한 접근을 추상화해서 개발자 편의를 제공하고 반복적인 데이터 접근 코드를 줄여준다.
그래서 스프링 데이터 JPA는 말 그대로 JPA에 특화된 기능을 제공한다.
(스프링 프레임워크 + JPA를 사용하면 스프링 데이터 JPA를 사용하면 좋다.)
🧐 스프링 데이터 JPA를 쓸 땐 @Repository를 안써도 되나요?
@Repository를 쓰면 컴포넌트 스캔을 해서 스프링 빈에 등록해주는데 스프링 데이터 JPA는 생략해도 된다.
스프링 데이터 JPA는 애플리케이션 실행할 때 basePackage에 있는 Repository Interface들을 찾아서 해당 Interface를 구현한 클래스를 동적으로 생성한 다음 스프링 빈으로 등록한다.
즉, 개발자가 위 MemberJpaRepository처럼 직접 구현 클래스를 만들지 않아도 된다.
org.springframework.data.repository의 repository를 구현한 클래스는 컴포넌트 스캔 대상이다.
따라서 스프링 데이터 JPA가 구현(Proxy객체 만들어서)해서 인젝션(의존성 주입) 해준다.
스프링 데이터 JPA를 구현한 인터페이스를 getClass()해보면 "com.sun.proxy.$Proxy110" 처럼 출력된다.
스프링 데이터 JPA가 제공하는 공통 인터페이스 사용해보자

스프링 데이터 JPA는 간단한 CRUD 기능을 공통으로 처리하는 JpaRepository 인터페이스를 제공한다.
그래서 위와같이 Interface로 상속받아 사용하는데 이 때 JpaRepository<엔티티클래스, 엔티티클래스의 PK 타입>을 지정한다.
이렇게만 만들어도 아까전에 구현한 MemberJpaRepository의 기능보다 더 다양하게 사용할 수 있다.
JpaRepository 인터페이스의 계층 구조

- T : 엔티티
- ID : 엔티티의 식별자 타입
- S : 엔티티와 그 자식 타입
여기서 계층 구조를보면 스프링 데이터 모듈이 있는데 이것은 스프링 데이터 프로젝트가 공통으로 사용하는 인터페이스이다.
이 공통으로 사용하는 인터페이스는 Repository, CrudRepository, PagingAndSortingRepository가 있다.
따라서 JpaRepository를 구현하면 org.springframework.data.repository도 사용하므로 자동으로 컴포넌트 스캔이 된다.
JpaRepository의 주요 메서드
- save(S) : 새로운 엔티티는 저장, 이미 있는 엔티티는 수정
- delete(T) : 엔티티 하나를 삭제. 내부에서 EntityManager.remove() 호출
- findOne(ID) : 엔티티 하나 조회. 내부에서 EntityManager.find() 호출
- getOne(ID) : 엔티티를 프록시로 조회. 내부에서 EntityManager.getReference() 호출
- findAll(...) : 모든 엔티티 조회. 정렬(Sort) 또는 페이징(Pageable) 조건을 파라미터 제공 가능
'Spring > JPA' 카테고리의 다른 글
| Spring Data JPA - DTO 직접 조회 (0) | 2022.04.15 |
|---|---|
| Spring Data JPA - 쿼리 메서드 기능 (0) | 2022.04.14 |
| JPA 객체지향 쿼리 언어 소개 (0) | 2022.04.05 |
| JPA 프록시 (즉시로딩, 지연로딩) (0) | 2022.03.29 |
| JPA 객체 생성 방법 (0) | 2022.03.10 |